Intro
Dans mon homelab, les mises à jour font partie de ces choses faciles à repousser.
Pas parce qu’elles sont compliquées, mais parce qu’elles sont manuelles. Je dois me connecter au bon système, vérifier l’état, appliquer les mises à jour, redémarrer si nécessaire, vérifier que tout revient correctement, puis répéter le même processus pour le composant suivant.
Et comme c’est manuel, je le garde généralement pour plus tard.
Quand Proxmox VE 9.1 est sorti, je voulais déjà mettre à jour mon cluster, mais pas manuellement. Puis Proxmox VE 9.2 est devenu disponible il y a quelques jours, et je n’avais toujours pas construit de processus propre autour de cela. C’était un bon déclencheur pour enfin commencer à automatiser les mises à jour des parties importantes de mon homelab.
L’objectif plus large est de simplifier et d’automatiser le patching de plusieurs composants clés :
- Proxmox VE
- OPNsense
- TrueNAS
J’ai décidé de commencer par Proxmox parce qu’il est central dans le lab, et parce qu’un workflow de mise à jour progressive est un bon candidat pour l’automatisation.
Les Outils Utilisés
Le processus de mise à jour est construit autour de quelques composants que j’utilise déjà dans le lab.
Proxmox VE est ma plateforme de virtualisation. Le cluster utilise aussi Ceph, donc avant de toucher à un nœud, je veux m’assurer que le cluster est en bonne santé et que Ceph remonte HEALTH_OK.
Ansible est utilisé pour décrire le workflow de mise à jour sous forme de playbook.
Semaphore UI est utilisé pour exécuter le playbook depuis une interface web et le planifier.
Ntfy est utilisé pour les notifications. Si les mises à jour sont planifiées, j’ai besoin de savoir quand quelque chose se passe, surtout si le cluster n’est pas prêt ou si une mise à jour échoue.
Création d’un Topic Ntfy Dédié
Avant de planifier quoi que ce soit, je voulais un canal de notification dédié au homelab.
J’ai créé un topic homelab dans Ntfy et un utilisateur dédié nommé semaphore avec un accès en écriture seule à ce topic.
ntfy user add semaphore
ntfy access semaphore homelab wo
L’idée est que Semaphore a uniquement besoin de publier des messages. Il n’a pas besoin d’un accès en lecture.
J’ai aussi ajouté le topic sur mon téléphone mobile afin de pouvoir recevoir des notifications lorsque l’automatisation s’exécute.
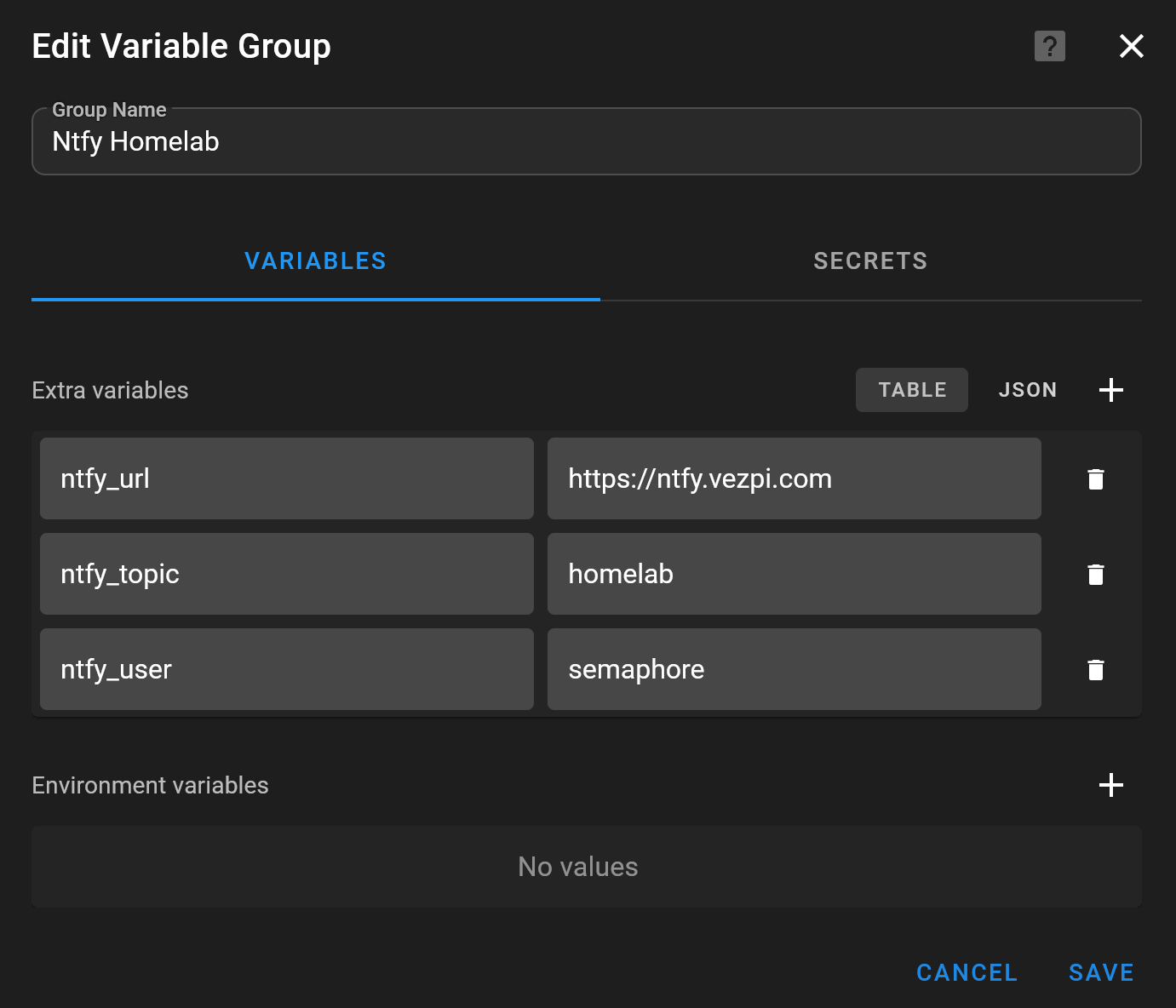
Dans Semaphore, j’ai créé un groupe de variables nommé Ntfy Homelab pour stocker les valeurs nécessaires aux playbooks :
ntfy_urlntfy_topicntfy_userNTFY_PASSWORD
Le mot de passe est stocké comme variable d’environnement dans l’onglet Secrets.
Conception du Workflow de Mise à Jour Proxmox
Pour Proxmox, je ne voulais pas d’un playbook qui exécute simplement apt upgrade sur tous les nœuds. À la place, il fait les actions suivantes :
- Vérifier la santé du cluster
- Arrêter et envoyer une notification Ntfy si le cluster n’est pas prêt
- Pour chaque nœud, vérifier si des mises à jour sont disponibles, et si oui :
- Activer le mode maintenance
- Attendre que les LXC et les VM quittent le nœud
- Mettre à jour les paquets
- Désactiver le rééquilibrage Ceph
- Redémarrer le nœud
- Activer le rééquilibrage Ceph
- Désactiver le mode maintenance
- Attendre que Ceph soit en bonne santé
- Envoyer un rapport Ntfy final
Le playbook complet est disponible sur mon dépôt Homelab
Détails du Workflow
Avant de démarrer la mise à jour progressive, le playbook vérifie :
- Le quorum du cluster Proxmox
- La santé de Ceph
Si l’une de ces vérifications échoue, le playbook s’arrête et envoie une notification Ntfy au lieu d’essayer de continuer.
- name: Verify cluster quorum
ansible.builtin.command: pvecm status
register: quorum_status
changed_when: false
failed_when: quorum_status.stdout is not search('Quorate:\\s*Yes')
- name: Verify Ceph health
ansible.builtin.command: ceph health
register: ceph_health
changed_when: false
failed_when: "'HEALTH_OK' not in ceph_health.stdout"
C’est une partie importante de l’automatisation. Une mise à jour planifiée ne doit pas continuer aveuglément si le cluster n’est pas dans un bon état.
Le playbook met à jour les nœuds Proxmox avec serial: 1.
Cela signifie qu’un seul nœud est traité à la fois, ce qui est exactement ce que je veux pour une mise à jour de cluster.
Pour chaque nœud, le playbook commence par rafraîchir les dépôts et vérifie si des mises à jour sont disponibles en utilisant le mode check d’Ansible.
- name: Refresh repositories
ansible.builtin.apt:
update_cache: true
- name: Check if updates are available
ansible.builtin.apt:
upgrade: dist
check_mode: true
register: apt_check
Si aucune mise à jour n’est disponible pour un nœud, la partie lourde du workflow est ignorée.
Si des mises à jour sont disponibles, le playbook stocke la version actuelle de Proxmox, active le mode maintenance, attend que les invités quittent le nœud, applique les mises à jour, redémarre le nœud, puis attend que Ceph soit de nouveau en bonne santé.
- name: Enable maintenance mode
ansible.builtin.command: >
ha-manager crm-command node-maintenance enable {{ inventory_hostname_short }}
Une fois le mode maintenance activé, le playbook attend qu’il ne reste plus aucun LXC en cours d’exécution sur le nœud :
- name: Wait for LXCs to leave node
ansible.builtin.shell: |
pct list | awk 'NR>1 && $2=="running" {count++} END {print count+0}'
register: lxc_count
changed_when: false
until: lxc_count.stdout | int == 0
retries: 60
delay: 15
Il fait la même chose pour les VM en cours d’exécution :
- name: Wait for VMs to leave node
ansible.builtin.shell: |
qm list | awk 'NR>1 && $3=="running" {count++} END {print count+0}'
register: vm_count
changed_when: false
until: vm_count.stdout | int == 0
retries: 60
delay: 15
Une fois que le nœud est vide, la mise à niveau des paquets peut s’exécuter :
- name: Update packages
ansible.builtin.apt:
upgrade: full
autoremove: true
autoclean: true
Avant de redémarrer, le playbook définit noout sur les OSD Ceph :
- name: Disable Ceph rebalancing
ansible.builtin.command: ceph osd set noout
Puis le nœud est redémarré :
- name: Reboot node
ansible.builtin.reboot:
reboot_timeout: 900
post_reboot_delay: 30
Après le redémarrage, le rééquilibrage Ceph est réactivé, le mode maintenance est désactivé, et le playbook attend que Ceph revienne à HEALTH_OK.
- name: Enable Ceph rebalancing
ansible.builtin.command: ceph osd unset noout
- name: Disable maintenance mode
ansible.builtin.command: >
ha-manager crm-command node-maintenance disable {{ inventory_hostname_short }}
- name: Wait for Ceph to be healthy
ansible.builtin.command: ceph health
register: ceph_status
changed_when: false
until: "'HEALTH_OK' in ceph_status.stdout"
retries: 60
delay: 15
delegate_to: "{{ groups['nodes'][0] }}"
Le résultat est une mise à jour progressive contrôlée au lieu d’une procédure manuelle nœud par nœud.
Envoi d’un Rapport de Mise à Jour
À la fin du workflow, le playbook envoie un rapport via Ntfy. Il détermine d’abord si au moins un nœud a été mis à jour :
- name: Determine if updates occurred
ansible.builtin.set_fact:
updates_performed: "{{ groups['nodes'] | map('extract', hostvars) | selectattr('update_report', 'defined') | list | length > 0 }}"
Ensuite, il envoie un message au topic homelab.
Si aucune mise à jour n’était disponible, la notification l’indique et utilise une priorité plus basse.
Si des mises à jour ont été appliquées, la notification liste les nœuds mis à jour et affiche la version de Proxmox avant et après la mise à jour.
La logique de rapport est basée sur le fact update_report sauvegardé pendant la mise à jour du nœud :
- name: Save update report
ansible.builtin.set_fact:
update_report:
old: "{{ pve_old_version.stdout }}"
new: "{{ pve_new_version.stdout }}"
Le corps de la notification construit ensuite un résumé à partir de tous les nœuds :
body: |
{% set updated_nodes = [] %}
{% for node in groups['nodes'] %}
{% if hostvars[node].update_report is defined %}
{% set _ = updated_nodes.append(node) %}
{% endif %}
{% endfor %}
{% if not updates_performed %}
No updates available on the cluster.
{% else %}
The following nodes were updated:
{% for node in updated_nodes %}
{% if hostvars[node].update_report.old == hostvars[node].update_report.new %}
- {{ hostvars[node].inventory_hostname_short }}: version {{ hostvars[node].update_report.old }} (unchanged)
{% else %}
- {{ hostvars[node].inventory_hostname_short }}: version {{ hostvars[node].update_report.old }} → {{ hostvars[node].update_report.new }}
{% endif %}
{% endfor %}
{% endif %}
Cela rend la tâche planifiée beaucoup plus facile à considérer comme fiable. Je n’ai pas besoin d’ouvrir Semaphore à chaque fois pour savoir ce qui s’est passé.
Exécuter le Playbook depuis Semaphore
Une fois le playbook prêt, je l’ai poussé dans le dépôt et j’ai configuré un modèle de tâche Semaphore pour l’exécuter.
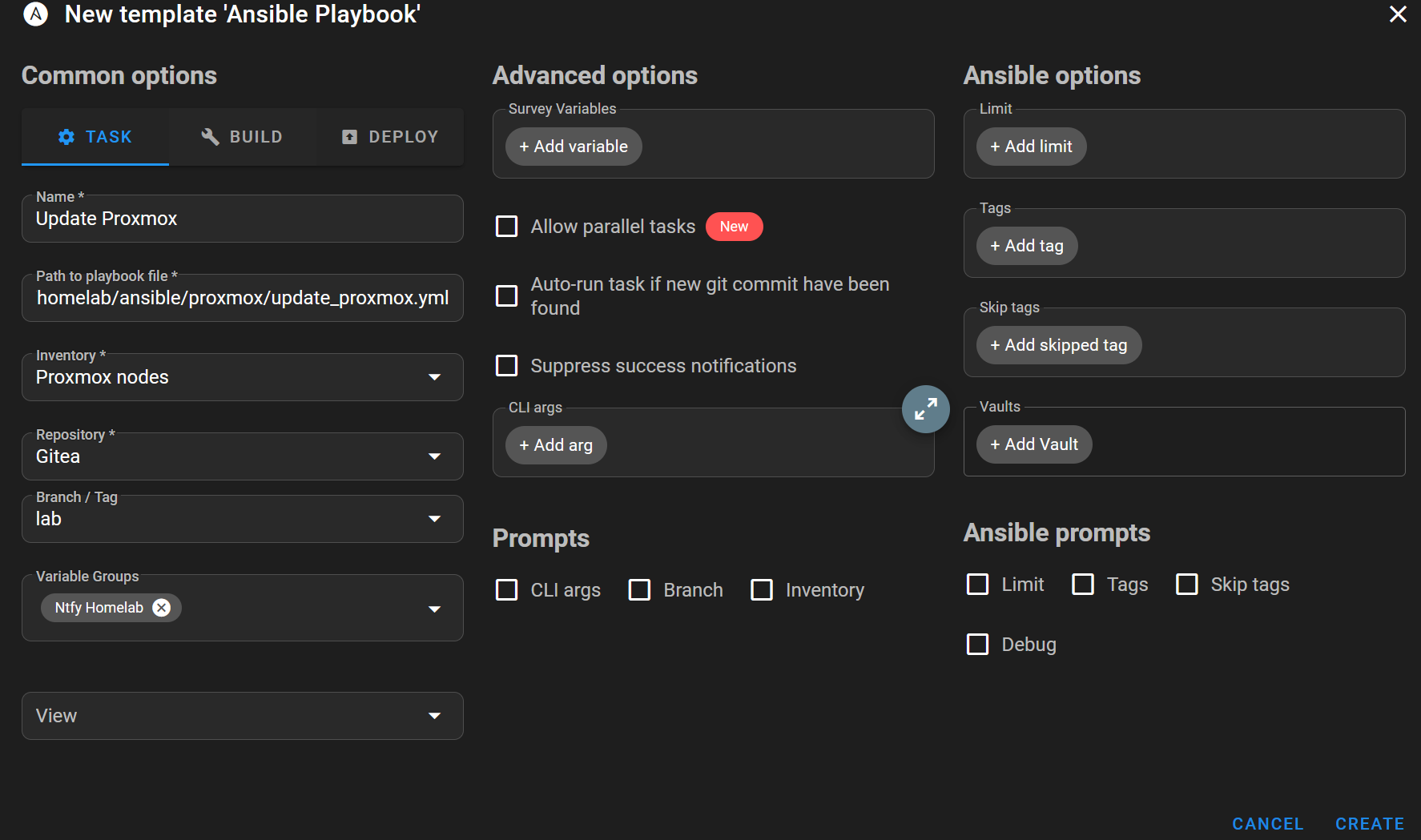
À partir de là, je pouvais lancer le workflow et le regarder agir sur le cluster.
Pendant l’exécution, le nœud cible entre en mode maintenance et les workloads en cours d’exécution sont migrés hors de celui-ci.
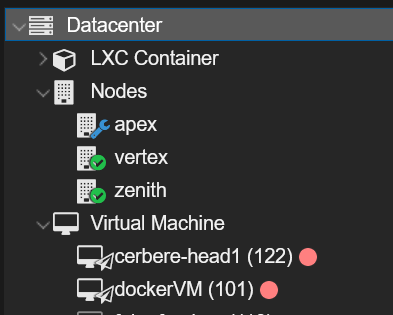
C’est à ce moment-là que l’automatisation devient vraiment utile. Le playbook n’applique pas seulement les mises à jour. Il prend aussi en charge les étapes opérationnelles autour de la mise à jour.
Planification de la Mise à Jour
Après avoir affiné le playbook et validé le workflow, j’ai créé une planification dans Semaphore.
Dans Schedule, j’ai cliqué sur New Schedule, sélectionné Cron, donné un nom, sélectionné une planification hebdomadaire, puis choisi le vendredi à 4h00 UTC.

À ce stade, le processus de mise à jour de Proxmox n’est plus quelque chose dont je dois me souvenir pour le faire manuellement.
Il s’exécute selon une planification, vérifie l’état du cluster avant de faire quoi que ce soit, met à jour un nœud à la fois, et envoie une notification avec le résultat.
Conclusion
Ce projet est parti d’un problème simple : je ne mettais pas mon homelab à jour régulièrement parce que le processus était encore trop manuel.
L’automatisation des mises à jour Proxmox était la première étape importante. La partie importante n’était pas seulement d’exécuter les mises à niveau de paquets, mais de les entourer des vérifications et des étapes opérationnelles qui ont du sens pour un cluster Proxmox avec Ceph.
Semaphore me donne une façon propre d’exécuter et de planifier le playbook. Ansible décrit le processus de manière répétable. Ntfy boucle la boucle en me disant ce qui s’est passé.
Les prochaines étapes logiques sont de continuer avec la même approche pour les autres composants clés du lab : OPNsense et TrueNAS.